我是Comlink-v1的重度用户,并在我的公司重努力推广它。
I am a heavy user of Comlink-v1 and have worked hard to promote it at my company.
它很棒,但仍然有一些问题,比如使用者必须知道它背后的工作原理,有时候还会因为参数传递时,对其进行序列化或者反序列化时引发一些低级的错误。
It's great, but still has some issues, such as the user having to know how it works behind the scenes, and sometimes triggering some low-level errors when serializing or deserializing it when passing parameters.
总的来说,Comlink-v1虽然有些瑕疵,但他解决了很多问题。
Overall, Comlink-v1 has some flaws, but it solves a lot of problems.
最近我重新思考Comlink-v1存在的一些缺陷,并且尝试对它进行重新实现。在几经尝试后,不得不说,那些缺陷真的很难规避,为此我不得不牺牲它的通用性。所以最终我还是将Comlink-v2给实现了出来。可惜的是我不能将源码公布出来,但我可以提供基础的实现思路。我相信,这个新的思路会给js领域带来新的魔力。
Recently I've been rethinking some of the flaws in Comlink-v1 and trying to re-implement it. After a few attempts, I have to say that those flaws are really hard to avoid, and for that I had to sacrifice its versatility. So I finally implemented Comlink-v2. Unfortunately I can't publish the source code, but I can provide the basic idea of the implementation. I believe that this new idea will bring new magic to the JS field.
这是已经通过测试的代码:
This is the code that has been tested:
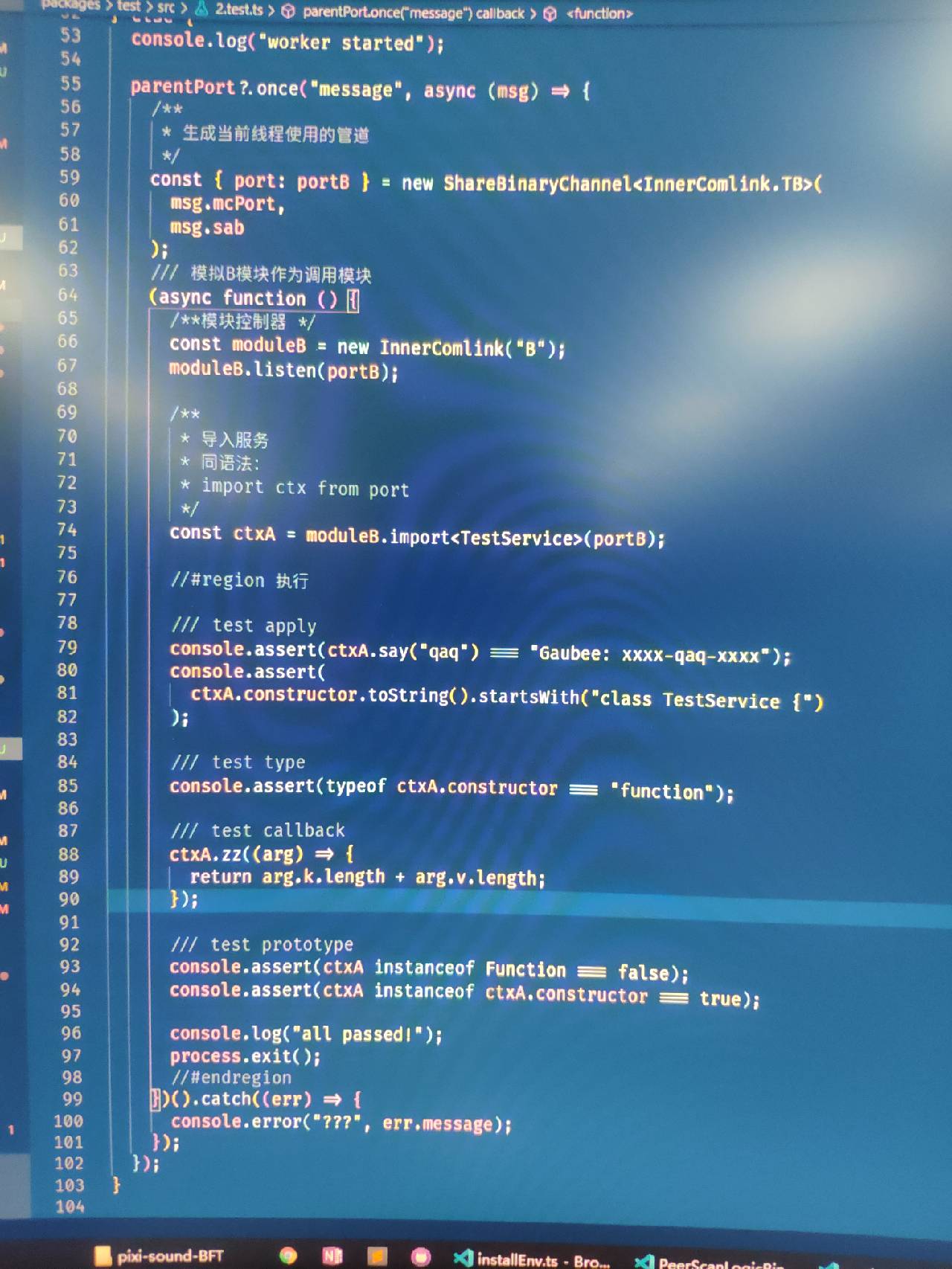 Effect Preview
Effect Preview众所周知,Comlink-v1使用await来隐式调用then函数的特性来实现的。
As you know, Comlink-v1 uses the feature of await to implicitly call the then function to do this.
在Comlink-v2中,我努力将所有异步给消除了。众所周知,在js中,同步是异步特性的根基,也正因此我们能将async/await编译成es5的代码来运行。所以理论上,只要在comlink重摆脱了异步的依赖,那么就彻底拥有了更多的语言特性。比如 instanceof、prop in obj 等等。
In Comlink-v2, I tried to eliminate all asynchrony. As you know, synchronization is the basis of asynchronous features in js, and that's why we can compile async/await into es5 code and run it. so theoretically, once we get rid of the asynchronous dependency in comlink, we have more features in the language. For example, instanceof, prop in obj, and so on.
为此,我使用Atomic.wait/notify这对API来实现。当然,在浏览器中,它必须在web-worker中才能正常使用。这确实带来了一些局限性,但相信我,最终的Comlink-v2所带来的特性将会把这些局限性间接消除。
For this, I use the Atomic.wait/notify pair of APIs. Of course, it has to work in a web-worker to work in a browser. This does introduce some limitations, but believe me, the features that will eventually come with Comlink-v2 will indirectly remove these limitations.
在Atomic-API的加持下,我们现在可以将一个worker暂停,等待其它线程执行完再将之唤醒。因此,你现在可以完全使用Proxy的魔力了。
With the addition of Atomic-API, we can now pause a worker and wait for other threads to finish executing before waking it up. So you can now use the full magic of Proxy.
接下来,要做工作主要有三方面:
There are three main areas of work to be done next.
- 要将数据分成三类:cloneable(string、number、boolean、bigint、null、undefined);symbol;reference(object、function)
To divide data into three categories: cloneable (string, number, boolean, bigint, null, undefined); symbol; reference (object, function)
- 使用Atomic来进行通讯
Using Atomic for communication
- 内存的引用与释放
Reference and release of memory
在Comlink-v2中,我们不再需要注册数据的序列化与反序列化,因为我们拥抱了同步。所以对于reference,我们统一使用Proxy来实现,这样能直接消除Comlink-v1的存有的各种副作用。正如你只是在同一个isolate中对一个引用对象进行代理一样。
In Comlink-v2, we no longer need serialization and deserialization of registration data, because we embrace synchronization. So for references, we use a unified Proxy implementation, which directly eliminates the various side effects present in Comlink-v1. Just as you would just proxy a reference object in the same isolate.
其次,就是symbol这个比较特殊的类型。我们无法对symbol进行Proxy代理,但依赖symbol的特性,在不同isolate中的symbol本身就是不共享的,我们可以在不同的isolate中创建一个副本,并为其注册唯一的id。
Secondly, there is the rather special type of symbol. We can't Proxy symbols, but relying on the properties of symbols, which are themselves unshared in different isolate, we can create a copy of the symbol in a different isolate and register a unique id for it.
关于Symbol有两点要注意:
There are two things to note about Symbol:
- 要使用
Symbol.keyFor来判断是否是使用Symbol.for创建的;
To use Symbol.keyFor to determine if it was created using Symbol.for.
- 我们还需要预先对
Symbol.iterator,Symbol.hasInstance...这些特殊的symbol进行预先注册。
We also need to pre-register the special symbols Symbol.iterator,Symbol.hasInstance....
接下来我们来谈谈如何使用Atomic来进行通讯:
Next let's talk about how to use Atomic for communication.
首先我们需要一个shareArrayBuffer,它用于存储两个线程通讯所需要的全部数据。但是我们不应该使用轮询到方式来让另一个线程知晓何时开始处理数据,所以我们还需要一个messageChannel,它的作用是用来通知另一个线程开始处理:
First we need a shareArrayBuffer, which is used to store all the data needed for the two workers to communicate. But we shouldn't use polling to let the other worker know when to start processing the data, so we also need a messageChannel, which is used to inform the other thread to start processing.
msgPort.postMesaage('Please wake me up');
Atomic.wait(sab_i32a,0,0);
接下来就会遇到一个问题,就是调用堆栈的问题。执行一个任务,两个线程可能需要进行多次的交互。
The next problem that comes up is the problem of calling the stack. Executing a task, two threads may need to interact multiple times.
所以我的解决方案是:记录调用堆栈长度:
So my solution is to record the call stack lengths:
msgPort.postMesaage('Please wake me up');
const stackLen = sab_i32a[0] = 1;
Atomic.wait(sab_i32a,0);
if (sab_i32a[0] === stackLen - 1)
最后,也是最重要的一点。因为我们模拟了JavaScript中的引用对象,所以,当我们导入一个对象,那么它就会被注册,也就意味着无法主动释放,如果强制释放,可能会造成其它线程使用refId(引用ID)来寻找时,才发现对象被释放,造成异常。
对此,我的解决方案是 WeakRef + FinalizationRegistry
Lastly, and most importantly. Since we simulate reference objects in JavaScript, when we import an object, then it is registered, which means that it cannot be actively released, and if it is forced to be released, it may cause an exception when other threads use refId (reference ID) to look for it, only to find that the object is released.
For this, my solution is WeakRef + FinalizationRegistry
只需要监听引用者的内存释放,从而来通知数据提供方的释放对象即可。唯一遗憾的是,我们无法监听symbol的释放。所以这点要特别注意,不要让两个线程交互过多的symbol。
You only need to listen to the referrer's memory release to notify the data provider of the released object. The only unfortunate thing is that we can't listen for symbol releases. So be careful not to let two workers interact with too many symbol.
虽然我们使用了同步作为基础作为通讯,但为了可以让其有更加丰富的使用场景,我们也应该支持异步。
Although we use synchronous as the basis for communication, we should also support asynchronous in order to have a richer use case for it.
如何让同一套代码同时兼容异步和同步呢?我的建议是使用callback:
How can we make the same set of code compatible with both asynchronous and synchronous? My suggestion would be to use callback.
let res;
flow.dosomething(1,2,3,(_res)=>res=_res);
console.log('callback ❤️ sync');
const res = new Promise(cb=>flow.dosomething(1,2,3,cb));
console.log('callback ❤️ async');
最后我来聊一聊它的一些特性所将带来的影响:
Let me conclude by talking about the impact that some of its features will have:
- 在浏览器中,我们完全可以使用Comlink-v2来代理主线程。从而将业务完全运行在web-worker中。但因为浏览器的局限性,我们需要结合同步和异步的接口来进行实现。这点很像在nodejs中开发native插件。
In the browser, we could have used Comlink-v2 to proxy the main thread. This allows us to run the business entirely in the web-worker. But because of browser limitations, we need to combine synchronous and asynchronous interfaces to do so. This is much like developing native plugins in nodejs.
- 我觉得这可以作为JavaScript并发的实现,它可以给我们带来很多想象。虽然Comlink-v1已经做到,但是同步的接口将会更加自然,开发者使用时,局限性更少:想象一下erlang的特性将会基于此实现~
I think this can be implemented as JavaScript concurrency, it can give us a lot to imagine. Although Comlink-v1 already does this, the synchronous interface will be more natural and less restrictive for developers to use: imagine the features of erlang will be based on this implementation ~!
- 因为少了注册模型的序列化与反序列化,所以它与其它语言更容易交互。(事实上这正是我们公司将要做的事情)
Because there is less serialization and deserialization of registration models, it is easier to interact with other languages. (In fact this is exactly what we are going to do at our company.)