状态机是目前库中所存在的一个高级的概念,它一定程度上是现有功能的一个组合,使用字符串指令针对状态机的操作,以下是其运作流程:
绑定一个事件
-> 这个事件是一个命令,目前有四种基础命令:
(赋值)=,(添加)+,(移除)-,(切换)?
-> 事件触发,动态解析命令对状态机进行相应的操作
(某种程度上就限制了效率的保证)
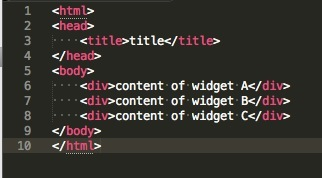
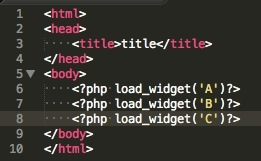
这四个基础命令都是统一的格式:双目运算符的格式。 左边的参数是目标key,字符串类型,所以这是可动态的:
{{" {{key}} = {{"static value"}} "}}
可以看到一个命令是一个字符串,而后两个参数都需要用{{}}进行包裹,其中第一个参数作为目标key,第二个参数是赋值内容,在源码不到白行的实现中也是很明了的知道其命令最终编译出来的代码是:
JS解决方案当然是最万能的。 所以这里主要讲的是CSS解决方案,整理自鬼懿IT高级群的讨论 10-11-2013。 先上一段官方的说辞:
The placeholder attribute represents a short hint (a word or short phrase) intended to aid the user with data entry. A hint could be a sample value or a brief description of the expected format. The attribute, if specified, must have a value that contains no U+000A LINE FEED (LF) or U+000D CARRIAGE RETURN (CR) characters.
1
首先要知道的是HTML属性中的值会原封不动地输出到页面中,所以:
<textarea placeholder="line1 \n lin2 <br> line3 \A line4
line5"></textarea>
是不会其任何作用的(这里line4和line5中的回车写法会被过滤掉,但是title属性就不会)。 所以就要借用到CSS。
2
先说webkit浏览器的解决方案:
Clouds. Have you ever noticed how much people moan about them? They get a bad rap. If you think about it, the English language has written into it negative associations towards the clouds. Someone who's down or depressed, they're under a cloud. And when there's bad news in store, there's a cloud on the horizon. I saw an article the other day. It was about problems with computer processing over the Internet. "A cloud over the cloud," was the headline. It seems like they're everyone's default doom-and-gloom metaphor. But I think they're beautiful, don't you? It's just that their beauty is missed because they're so omnipresent, so, I don't know, commonplace,
原文地址:http://avnpc.com/pages/start-a-modular-extensible-webapp 作者:Allo Vince
虽然从没有认为自己是一个前端开发者,但不知不觉中也积累下了一些前端开发的经验。正巧之前碰到一道面试题,于是就顺便梳理了一下自己关于Web App的一些思路并整理为本文。
对于很多简单的网站或Web应用来说,引入jQuery以及一些插件,在当前页面内写入简单逻辑已经可以满足大部分需要。但是如果一旦多人开发,应用的复杂程度上升,就会有很多问题开始暴露出来:
- 数据源一般都与页面分离,那么App启动一般都需要等待数据源读入。
- UI交互复杂时,需要将逻辑通过面向对象抽象后才能更好的复用。
- 功能间一般都存在依赖关系,需要引入支持依赖关系的模块加载器。
那么如何解决这些问题,就以一个简单的订餐App为例,从零开始一个模块化可扩展Web App。
这个简单的App基于HTML5 Boilerplate、requireJS、jQuery Mobile、Underscore.js,后端逻辑用jStorage模拟实现。完成后的成品在此。所有代码可以在github查看。下文将逐一介绍实现的思路与方法。
从选择一个好模板开始
开始一个Web项目,HTML的书写总是重中之重,一个好的HTML能从根源上规避大量潜在问题,所以Web App应该全部应用一个标准化的高质量HTML模板,而不是将所有页面交由开发人员自由发挥。
这里推荐使用HTML5 Boilerplate项目作为App的默认模板以及文件路径规范,无论是网站或者富UI的App,都可以采用这个模板作为起步。
作者:柳鸣九 来源:《最爱北京人》
早在做同事之前,在东四头条的社科院宿舍大院,我和杨绛先生就做过邻居,于是比起别人,我便多了一些熟悉与就近景仰的机会。按“翰林院”(中国社会科学院)不成文的规矩,对她这样的旧时代过来的海归大家,作为小字辈的我,要按其本名,尊称她“季康先生”。
初见时,季康先生年过半百,精瘦娇小,举止文静轻柔,但整个人极有精神,特别是两道遒劲高挑而又急骤下折的弯眉,显示出一种坚毅刚强的性格。和其夫君锺书先生的不拘小节、有时穿着背心短裤就见客不同,她的衣着从来都整齐利索,即使在家不意碰见来访者敲门的时候。
当时研究所有两位女士以注重形象着称。一是“九叶诗人”之一的郑敏,她是美国式的艳丽和浪漫风格;另一位则是杨季康,典雅华贵,冬天常披一件裘皮大衣,很是高雅气派。这二位都保持着西洋妇女那种特定的“尊重自己,也尊重别人”的习惯,每次在公共场合露面,都对面部做了不同程度的上妆,这在上世纪五六十年代的北京,是极罕见的。不过,前者的妆较浓,而季康先生的则几乎不着痕迹,似有似无。
在公众场合,季康先生从来都是低姿态的,她脸上总是挂着一丝谦逊的微笑。在学习会以及其他重要的场合中,季康先生极少发言、表态,实在不得不讲几句的时候,她总是把自己的语言压缩到最少。当时我们想:杨老太这是在“刘备种菜园子”吧。多年后看到她以“点烦”原则(即把用词精简到不可能再精简的程度)翻译《堂吉诃德》,才发现,这不仅是真正发自内心地尊重人,而且真正做到了会尊重人。
在我见到的大家名流中,钱、杨二位先生要算是最为平实,甚至最为谦逊的两位。季康先生虽然有时穿得雍容华贵,神情态度却平和得像邻里阿姨,而不像某些女才人那样,相识见面言必谈学术文化,似乎不那样就显不出自己的身份与高雅。认识久了,她对晚辈后生则有愈来愈多的亲切关怀,的的确确像一个慈祥的阿姨。
但这个看似低调谦恭的阿姨,也有吃了熊心豹子胆的时候,且这个时候出现得无比不合时宜。“文革”之初,他们被造反派揪出来,挂了牌子押上批斗会。可杨季康对“天兵天将”的推推搡搡公然进行了反抗,而且怒目而视。这还了得!在批斗会上,那么多党内老资格的革命干部,哪个不是服服帖帖?于是盛怒之下的造反派对她狠加惩罚,给她剃了个阴阳头。我第一次惊奇地感到季康先生性格中的凛然。要知道,“牛棚”里有不少从火线上转业过来的老战士,没有一个敢于如此维护自己被践踏了的尊严。
“文革”后期,钱、杨二位先生尚未获得平反,有家回不了,四处流转。更多像我们这样的“小人物”,也在苦等“落实政策”,精神备受煎熬。同是天涯沦落人,处境谁也不比谁强到哪儿去。说起来先生们在浩劫中失去的,远比我们要多得多,但对于这群甚至未能为他们说句公道话的晚辈,他们以极高的涵养、含蓄内敛且从不显于言辞的方式予以理解、宽容和无私帮助。
有一次,我家因额外开支经济上一时告急,杨先生得知后主动支援了我们几百元钱。后来有一天,她的助手递给我一个小纸包,里面有二十元人民币,“这是先生要我交给你们的,补贴你们的家用,要你们收下,什么道谢的话都不要讲。”那个时期,我与妻子朱虹两人的工资加起来只有一百三四十元,承担着抚养两个孩子与赡养双方父母的责任,由于业务断了路,没有半点稿费收入,生活的确相当清苦。先生雪中送炭,我们只好恭敬不如从命。没有想到,到了第二个月,又有一个小纸包。然后,第三个月,第四个月……
The stories we tell about each other
我们互相讲述的故事
matter very much.
非常重要
The stories we tell ourselves about our own lives matter.
我们谈论与自己生活相关故事是有意义的
And most of all,
而我认为最重要的是
I think the way that we participate in each other's stories
韩寒
其实我本来不想写这篇文章的,因为写了肯定会引来口水之争的,而我已经不想再去和别人争论什么。我曾经说过,如果我愿意,我可以去颠覆你们二十多年来形成的价值观,因为生活中很多在你们看来是理所当然的观念都是错误的,但后来马上删掉了这句话,因为我不想引来争论,并且改正你们对这个世界的认识对我来说没有任何的益处,而不是我不能。西南大旱,近200天没有下雨了,对西南的百姓的生活造成了极坏了影响,于是乎,广大人民再一次涌现了爱心精神,捐款的捐款,捐水的捐水。这是在汶川地震之后,又一调动全国人民积极性的事情。
捐款捐水,属于献爱心的行为,是一种高尚的行为,本身并没有可以指责的地方,相反,这是我国人民巨大民族凝聚力的体现。但我想说,并不是好的出发点都能带来好的结果。表面上,很多人的善举是在帮助西南的百姓,但我想说,你们的爱心举动使这场灾害的主角政府退到了幕后,而你们的行为并不能给西南的抗旱带来多大的帮助。在某种程度上,你们在帮西南百姓的倒忙。
我不知道大家发现一个问题没有,中国的灾害都是突然降临的,突然的出现在全国人民的面前。如果说地震我还能理解的话,那么干旱我实在难以理解。干旱的形成不是一天两天形成的,等到媒体关注的时候已经180多天没下雨了,我不知道媒体为什么不是在170天的时候关注的,为什么不是在160天的时候关注的,而偏偏是在180天以后才开始关注,而且是齐刷刷的关注。
难道非要等到180天之后干旱才能算是干旱?180天之后的干旱才能对人的生活产生影响?前两年的河南干旱也一样,等河南的农作物要绝收了,政府突然一下子蹦了出来,说救旱。我就想问,政府早干什么去了?前几天开两会的时候西南的干旱怎么没人来关注?旱情不怎么严重的时候怎么不来关注?农作物还没有绝收的时候怎么没人来救旱?现在出来救旱,能有多大效果?这完全是政府的失责,而你们的热情掩盖了政府的失责。而这种失责不受追究的结果就是在以后,这种事情还会继续发生。
四川地震就是活生生的例子,汶川地震之后,对相关官员责任的追究最后不了了之,虽然经过地震之后,四川的学校建筑可能会比以前结实一点,但我想说,当下次的地震不再是四川,而换个别的地方,四川的悲剧依然会再现。
记得以前看过一篇文章,记者采访一个捐助者,问:如果你捐的钱会被人贪污了,你还会捐吗?那人回答说:会的,如果我捐了100,被贪污了90,至少还会有10元能到达那些需要帮助的人手中,而如果我不捐,那些人连一分钱都没有。报道发出后,很多人感动的一塌糊涂。从表面上看,是这样的。对于这样的人,我只能以好人来形容,而不能冠以对社会有贡献的人。我说过,好的出发点不一定就能带来好的结果。
如果你以为那些受灾的人拿到你捐的那一点钱之后你就成功的帮助了他们,我只能说,你真的很无知,虽然是个好人。因为,你的那一点捐助不是在帮助他们,而是间接的害了他们。因为有些事情由民众来做,其效果真的微乎其微。
德国在17世纪就开始推行全民义务教育,而日本在明治末年的义务教育入学率比中国2000年的义务教育入学率要高。所以,当别的国家早早就成为发达国家,而中国还在为“小康”奋斗时,不要心里不平衡,这很正常。
不要心里不平衡,这很正常。不要跟我说中国国情不同,我不知道对于日本这样一个人口众多,土地贫瘠,资源匮乏的“日本国情”十分突出的国家,是如何成为世界第二号强国的,他们似乎连成为发达国家都没有理由,但他们做到了,事在人为。对于那些“我跟他谈国情,他和我谈接轨,我和他谈接轨,他和我谈国情”的人,我只想说,你的智商,充其量只配在别人把你卖了之后帮别人数数钱。
在博客园上看到EtherDream的JavaScript 上万关键字瞬间匹配这篇文章,感觉不错。于是改了DEMO里面的代码(耦合度是在是太高了,几乎得重新一遍才行……)
这种方法的有点就是:树形的结构擅长于同时匹配多个关键字。单个关键字来说,直接用indexOf来查询、切割字符串,速度更快。
改动主要在两个方面:
- 对语句规范化(JSHint规范);
- 改写了一部分语句,核心的语句效率几乎是达到最大,比如
if(match === true) 比 if(match) 快,另外把得出的匹配结果可读化,这个有点耗资源,不过有它存在的必要性,在后期处理数据时更快。
核心代码:
var treeSearch = {
makeTree: function(strKeys) {
"use strict";
var tblCur = {},
tblRoot,
key,
str_key,
Length,